
Welches LLM für Datenextraktion?
Die kurze Antwort war hier OpenAI, nachdem wir Mistral, OpenAI und Gemini verglichen haben — aber die längere Antwort ist ein bisschen “kommt drauf an” und “du musst dich nicht auf ein Modell festlegen”. Was wir in diesem Fall gemacht haben, um das herauszufinden: die Ergebnisse mit n8n-Evaluations gemessen.
Die Kunden-Frage
Unser Kunde hat uns gefragt: “Welches KI-Modell ist das beste für mein Dokumenten-Datenextraktions-Automationsprojekt? Mit Google Gemini hatten wir gute Ergebnisse.” Anthropic wurde auch als Option genannt. Weil wir nicht auf das Bauchgefühl und die “Vertrau mir, Bruder”-Statistik setzen wollten, mussten wir Zahlen liefern — vergleichbare Zahlen. Denn was will der Kunde, wenn er ein Modell auswählt?
- das billigste
- das schnellste
- das genaueste
Wobei “das genaueste” der wichtigste Teil ist. Es bringt nichts, billig und schnell zu sein, wenn die Extraktion falsch ist. Und: Du kannst dir nur zwei davon aussuchen, alle drei gibt es nicht!
Einfach OpenAI nehmen?
Naja, kommt drauf an. Jede Aufgabe hat andere Anforderungen, und du musst es messen und testen. Dein Bauchgefühl zum Ergebnis skaliert nicht und beweist nichts. Willst du erkennen, ob ein Bild handgeschriebenen Text enthält? Dann nimm dafür nicht Mistral OCR — das extrahiert einfach den Text; hier wäre Gemini die bessere Wahl. Willst du OCR in einem strukturierten Format extrahieren? Mit Gemini kann das tricky werden, nimm dafür Mistral. Es ist die übliche langweilige Antwort: “kommt drauf an”.
OpenAI vs. Gemini vs. Mistral bei Datenextraktion
Wenn es darum geht, Bilder oder PDFs in Text umzuwandeln, vergessen die meisten Mistral. Die OCR-Fähigkeiten und die Geschwindigkeit von Mistral sind bisher unübertroffen — kein Prompt, kein kompliziertes Setup. Du wirfst ihm ein PDF oder ein Bild hin und bekommst in beeindruckender Geschwindigkeit Text zurück. Dafür haben wir uns gar nicht die Mühe gemacht, Messungen zu erstellen — ich weiß, der Beitrag heißt “wir haben es gemessen”, wir kommen dazu, versprochen. Beim Extrahieren der Daten lief das Setup aber über n8n-Evaluations: ein bisschen Testdaten mit erwarteten Ergebnissen anlegen und dann den Workflow durch die Evaluations laufen lassen.
Was wir gebaut haben: das Evaluations-System
Das Evaluations-System zu bauen ist nicht so schwer: Du nimmst dir einen Stapel Testdaten, speicherst das OCR in einer Datatable, dazu das erwartete Ergebnis. Wenn das Ergebnis ein komplexeres JSON ist, könntest du eine KI als Schiedsrichter über die Korrektheit entscheiden lassen — wir bevorzugen aber den deterministischen Weg über String-Ähnlichkeit. Damit vergleichst du dein erwartetes Ergebnis mit dem, was das LLM erzeugt hat. Es gibt ein paar Stolperfallen, auf die du achten musst — dazu mehr im nächsten Abschnitt.
Wie wir die Genauigkeit bewerten
Nehmen wir an, du extrahierst Daten aus Belegen, die buchhalterisch relevant sind.
- Vergleich nur, was zählt — ignorier kosmetische Abweichungen (vergleich die buchhaltungsrelevanten Felder, nicht Wortlaut oder Schlüsselreihenfolge).
- Normalisier vor dem Vergleich (sortierte Keys / Deep-Equal, kein roher String-Abgleich).
- Trenne “Extraktion” von “Berechnung”: das Modell soll nur transkribieren, was auf dem Beleg steht; deterministische Mathematik gehört in den Code. Das ist die mit Abstand wichtigste Lektion für Genauigkeit und Stabilität — killt Drift zwischen Läufen. Lass das Modell nicht das tun, was deterministischer Code besser kann.
- Erzeug Baselines nach jeder Änderung neu; lies die Richtung des Diffs (nicht jede Änderung ist eine Regression).
Okay, da ist einiges drin.
Vergleich nur, was zählt
Nicht jeder Text vom Beleg muss perfekt sein. Die Belegnummer von einer Tankquittung ist nicht so wichtig — die Menge des Treibstoffs und der Preis aber schon. Solche Daten musst du beim Vergleichen rausnehmen, in deinen Ergebnissen genauso wie in den Baseline-Daten.
Normalisier vor dem Vergleich
Einen JSON-String zu vergleichen kann funktionieren, wenn das Modell die Struktur und Sortierung immer gleich hält. Hier glänzt der n8n Structured Data Parser — es hängt aber auch vom Modell ab. Manche behalten die Key-Sortierung bei, andere weichen ab, was beim Vergleich auf String-Ebene Probleme machen kann.
Trenne “Extraktion” von “Berechnung”
LASS DAS LLM KEINE MATHEMATIK MACHEN — auch wenn du ihm einen Taschenrechner-Tool gibst, das bringt nichts. Alle benötigten Daten MÜSSEN auf dem Beleg stehen; wenn nicht, ist eher der Beleg das Problem. Es gibt Fälle, wo gerechnet werden muss. Manche Belege haben Bruttopreise, andere Nettopreise. Um das zu normalisieren, nimm einen Code Node, der die fehlenden Daten generiert. Die KI soll extrahieren, was da ist — und wenn etwas zu berechnen ist, mach das per Code. Noch was Wichtiges im Berechnungsteil: prüf, ob alles aufgeht. Manchmal liest die OCR Zahlen falsch — wenn es nicht aufgeht (Positionen + USt = Summe), dann stimmt was nicht und ein Mensch muss draufschauen.
Erzeug Baselines nach jeder Änderung neu; lies die Richtung des Diffs
Das ist der harte und zeitaufwendige Teil. Bei jedem Lauf die Ergebnisse prüfen, die Unterschiede verifizieren, die Baseline für die Evaluations neu erzeugen. Diesen Schritt MUSST du manuell machen — das einem LLM zu überlassen, fliegt dir später um die Ohren. Noch ein Tipp: Hab eine KI in den Evaluations, die die Unterschiede prüft und protokolliert. So siehst du auf einen Blick, was abweicht und was zu fixen ist. Noch ein Tipp: n8n rundet die Eval-Ergebnisse — wenn du also eine 0,99 hast, zeigt es 100 %, aber irgendwo ist trotzdem ein Unterschied. Diese Diffs in eine Datatable zu loggen hilft dir, das schnell zu erkennen.
Wie läuft der Eval ab
Der Evaluations-Lauf ist ziemlich geradlinig:
- Testdaten aus Datatables lesen
- das OCR durch das LLM schicken
- durch den Compute Node laufen lassen
- Daten rausstreichen, die wir für die Evaluation nicht brauchen (passiert nur im Evaluation-Zweig!)
- die Ergebnisse vergleichen
- alle Unterschiede loggen, wenn kein perfekter Match rauskommt
Head-to-Head-Ergebnisse — die Auszahlung
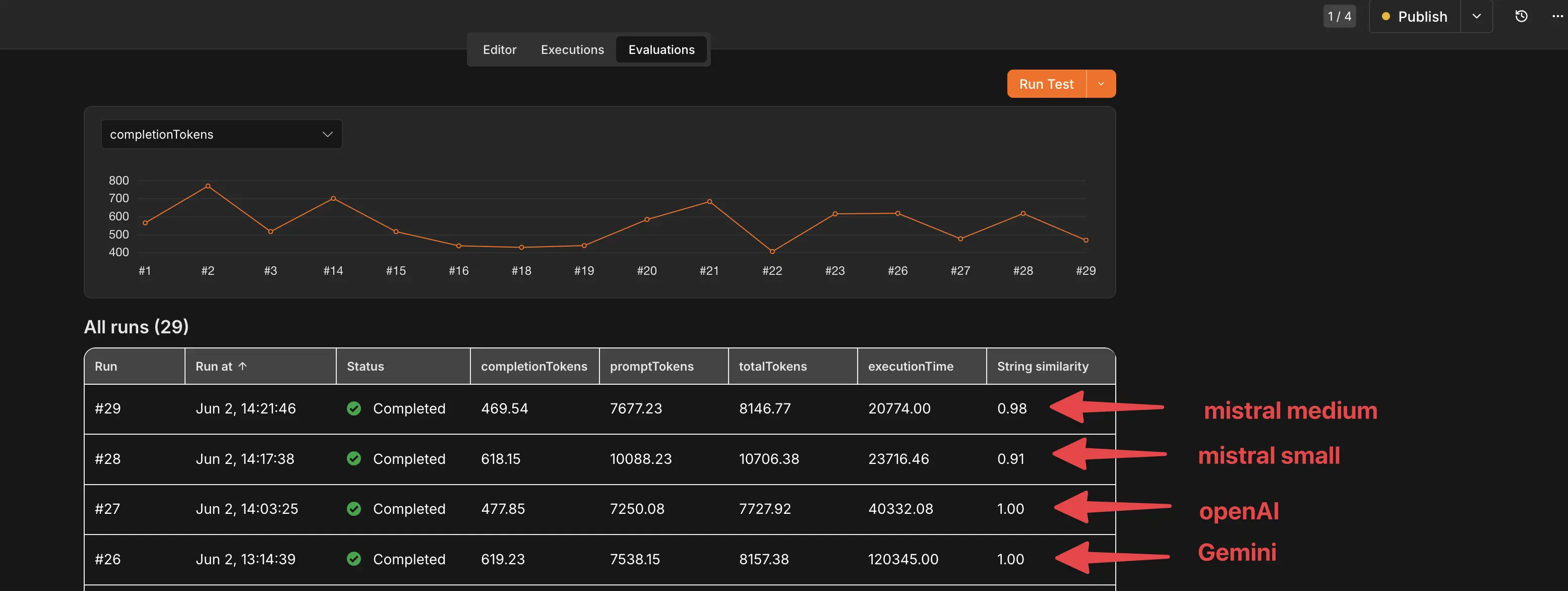
Wie du in den Evaluations-Ergebnissen siehst, liefern Gemini und OpenAI beide einen perfekten Score — aber die Laufzeit bei Gemini ist im Vergleich zu OpenAI irre. Zugegeben: Nicht jeder Gemini-Lauf hat so lang gedauert, aber erwähnen will ich es trotzdem. Mistral hat dagegen nicht so gut abgeschnitten. Es gäbe Spielraum, am Prompt, am JSON-Schema und am LLM-Setup nachzubessern — angesichts der aktuellen Ergebnisse und der Einfachheit, OpenAI als Modell zu nehmen, war aber ziemlich klar, welches Modell es wird. Damit wäre die Frage, welches Modell, beantwortet, oder? Ja, hier war OpenAI als Hauptmodell und Gemini als Backup unsere Wahl — es bleibt aber ein bisschen tricky, dazu komme ich gleich.
Die Auszahlung
Hier ist die echte Auszahlung dieser Evaluations. Bei mehreren Tests haben wir einen Bug im Code Node entdeckt — kein großes Ding, schnell gefixt. Aber was heißt das jetzt? Wie wirkt sich diese Änderung auf die anderen Belege aus? Und genau hier liegt das Geniale an n8n-Evaluations! Du startest sie und hast nach jeder Änderung Feedback, was dein Workflow tut.
Schau dir nur diese Ergebnisse an:
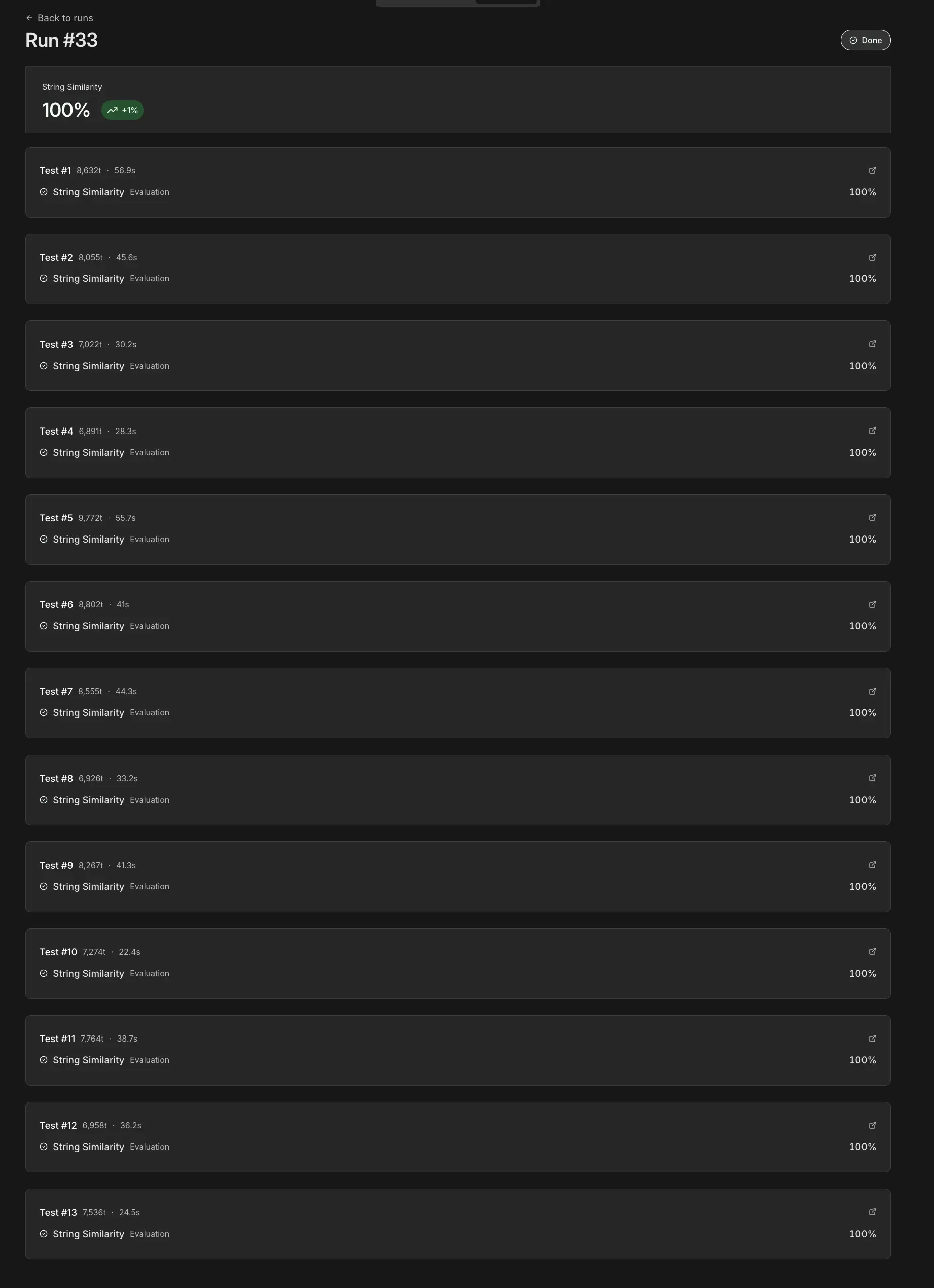
Gibt dir das nicht ein gutes Gefühl?
Warum nicht Gemini?
Wir nutzen JSON Schema und keine JSON-Beispiele beim Extrahieren von Daten. JSON-Beispiele sind ein Vorschlag, den das LLM überschreiben kann — JSON Schemas werfen einen Fehler, wenn die extrahierten Daten nicht gegen das Schema validieren. Gemini hat dabei einen anderen Ansatz als OpenAI, Mistral oder Anthropic. Das Schema akzeptiert keine Default-Werte und hat ein paar weitere kleine Eigenheiten, was die Arbeit damit tricky macht. Man könnte Gemini trotzdem fürs Extrahieren nehmen und ein anderes Modell als Orchestrator, der das JSON Schema zusammenbaut — aber wenn man sich die Laufzeiten anschaut, ist OpenAI hier die bessere Wahl.
Dein Take-away: Evals sind ein Regressionstest
- Du hast irgendwas am Prompt geändert? Woher weißt du, dass alles noch läuft? → Lass die Evaluations laufen.
- Du hast Code oder den Workflow geändert? Woher weißt du, dass alles noch läuft? → Lass die Evaluations laufen.
Ich glaube, du verstehst, worauf es hinausläuft.
FAQ
Wie misst du die Genauigkeit eines LLM bei der Datenextraktion?
Kommt auf den Fall an, üblicherweise mit String-Ähnlichkeit — auch wenn ich vorgeschlagen habe, lieber was anderes zu probieren. Es ist der einfachste Weg, und wenn das Modell die JSON-Struktur einhält, funktioniert String-Ähnlichkeit großartig.
Was ist ein LLM-Eval / Evaluation-Set?
Du brauchst Testdaten und ein erwartetes Ergebnis, das du dann vergleichen kannst. Datatable ist dafür ideal — schnell, eingebaut und einfach zu handhaben. Etwa so simpel wie das:
| OCR | expected_result | actual_result |
|---|---|---|
| xxx | { … } | null |
| Wenn deine Evals laufen, füllst du das actual_result und lässt den Eval-Check-Node das Ergebnis bewerten. |
Wie stark verändert die Modellwahl die Kosten?
Stark! n8n zeigt dir zwar nicht die Kosten pro Modell, aber die Anzahl der Tokens, die während des Tests benutzt wurden. Wenn du diese Zahl mit dem Preis deines LLM-Anbieters kombinierst, siehst du leicht, welcher günstiger und welcher teurer ist.
Wie geht’s weiter?
Wir bauen zuverlässige Extraktions-Workflows und Testdaten, um unsere Workflows zu messen und zu testen. Brauchst du Hilfe? Du kannst dich bei uns melden oder einen kurzen Videocall buchen.
Foto von Sophia Kunkel auf Unsplash