
I had Spec Kit on my radar for a while and took some time last week to play with it and better understand what issues it solves. Was I in for a very pleasant surprise.
The TL;DR Version: I had a very detailed list of tasks that needed completion, full documentation on the setup and broad knowledge of the industry details the app was developed for. Even if I would not have let the AI do the coding, this preparation alone that delivers a detailed task list and documentation is absolutely worth it.
The demo project
I decided to take a rather old project and not refactor / update it, but create it from scratch. It’s an API only server that takes in SMS via API requests does the routing to the appropriate carrier in the background and sends out the message. But there are some more details to think about, billing, fallback carrier, retries and marking the carrier as faulty, API credentials, permitted sender for each API client or multiple permitted senders. All in all not very complex but also not as trivial as it seems at first. Time to get started with spec kit and claude code.
The speck kit’s steps
You would start of with the constituion step that defines the general guidelines for the project, what tools to use, how to create the code and what to do or not to do.
You should definitely review this file after it’s creation and adapt it to your requirements.
Think of it like giving guidelines to a new junior dev.
Here some examples of my constitution:
All code MUST adhere to Rails 8.1+ conventions and leverage modern framework features:
- Leverage Solid Queue for background jobs instead of external job processors
- Utilize Solid Cache and Solid Cable for caching and WebSockets
- Follow RESTful API design patterns for all endpoints
- Implement proper ActiveRecord associations, validations, and scopes
- Use database-level constraints and indexes for data integrity
- Prefer convention over configuration; justify any deviation from Rails conventions
- use UUID for primary keys instead of auto-incrementing integers
And of course it continues with details about using rubocop, creating specs, test coverage and so on. Reading and updating this document should be a requirement in every project, regardless if you use AI or not. The fact that it’s created in a few seconds makes it so much more powerful.
specify the feature
Ok, now it’s time to specify what feature you want to build. No technical details, as it says in the spec kit documentation: Focus on the what and why
My input here was:
Input: “I would like to build an SMS Gateway API which takes in SMS that need to be sent and then decides based on given rules which outbound carrier it will use to deliver the SMS. It must keep track of which messages have been sent over what carrier for later billing checks. Keeping GDPR in mind, messages need to be anonymized as soon as possible (recipient and content) and be fully deleted after 6 months. It must be extendable to allow the usage of multiple outbound carriers, allowing the usage of fallback carriers but also distribute messages over carriers for example by giving it a 80-20% configuration which would send 80% of the messages over one carrier and 20% over another.”
so very short, broad overview of what I want to build. Claude code went ahead and created a very detailed specification of the tasks at hand. Take the GDPR user story for example:
Acceptance Scenarios:
- Given a message is successfully delivered, When delivery confirmation is received from the carrier, Then the system immediately anonymizes the recipient phone number and message content while preserving billing metadata
- Given a message delivery permanently fails after all retries, When the failure is recorded, Then the system anonymizes the recipient and content data
- Given message records exist in the system, When they reach 6 months of age, Then the system automatically and permanently deletes all records including anonymized metadata
- Given anonymization has occurred, When querying message details, Then original recipient and content data cannot be retrieved by any means
Here is where the AI knowledge comes in very handy. Did I mention anything about the format of the number where the message is to be sent? (E.164 for the Telecommunication nerds) or anything about the fact that SMS are billed based on the length? Think of a junior dev, who probably didn’t grow up in the SMS era and knowing that SMS used to be 160 Chars limited and later phones supported long messages but they where billed based on a per 160 character basis (160 characters = 1 SMS).
Spec Kit created, besides a lot of other requirements, these nuggets here:
- FR-005: System MUST support international phone number formats (E.164 standard assumed)
- FR-019: System MUST count message count on a per 160 character basis (160 characters = 1 SMS) since longer messages are split into multiple SMS by the carrier automatically and billed depending on their length
and even created a out of scope section:
- Multi-part/concatenated SMS handling (assumed single messages initially, or handled by carriers)
- Rich media messaging (MMS) - SMS text only
- Two-way conversations or reply handling
Clarify unclear requirements
Spec Kit might ask a few clarification questions during the specification process but you can, and should, run a separate /clarify task which will bring up a few interesting questions that maybe will make you think a bit about the task at hand as well.
Planing
Now it’s time to let Claude code do the planing and research. The created plan will have a very nice overview of what files will be created and give you an idea of how the code will be implemented. But the plan is not all that will be created, you will also get a very detailed research output.
The research output
The research output will be a very detailed plan and examples of code, tests and used tools (or in this case ruby gems). How the GDPR part will be implemented, how the carrier routing will be implemented, Authentication and API Keys, example curl calls to the API so you can get an idea of how the requests will work.
Not only will you get a plan of these details but also what alternatives exist and why they were excluded.
For example why go with Solid Queue instead of good old cron?
Alternatives Considered
- Cron jobs: Rejected because requires external cron configuration
- Whenever gem: Rejected because Solid Queue provides equivalent functionality
- Manual triggers: Rejected because automation ensures GDPR compliance
Remember the part where I mentioned the 160 char limit? Well, actually, it’s a bit trickier than that because the SMS will cut off a few bytes in order to save the concatenation bytes so that your phone will know it’s required to reassemble the split messages. Also I never mentioned that it is using the good old GSM-7 encoding (please don’t remind me of this trauma). Which gives this spot on part in the research:
Message Length Billing Calculation
Decision
Calculate SMS count based on 160-character segments (GSM-7 encoding assumed). Longer messages count as multiple SMS for billing.
Rationale
- Carrier standard: Most carriers bill per 160-character segment
- Concatenation: Messages >160 chars split by carrier into multiple SMS
- Header overhead: Concatenated messages use ~7 chars per segment for headers (153 usable chars per segment after first)
Algorithm
# app/services/billing_calculation_service.rb
def calculate_sms_count(message_content)
length = message_content.length
return 1 if length <= 160
# Concatenated messages: first segment = 153 chars, subsequent = 153 chars
segments = (length / 153.0).ceil
segments
end
You get the idea, just imagine the meeting with your junior or team to discuss these issues and plan out everything. All the while the AI was creating this, I was either preparing my kids something to eat or learning something new.
More goodies from the planning task
But wait, there’s more! (Yes I know this sounds like typical TV Sales ad)
Entity Relationship Diagram
You get a nice Entity Relationship Diagram in markdown
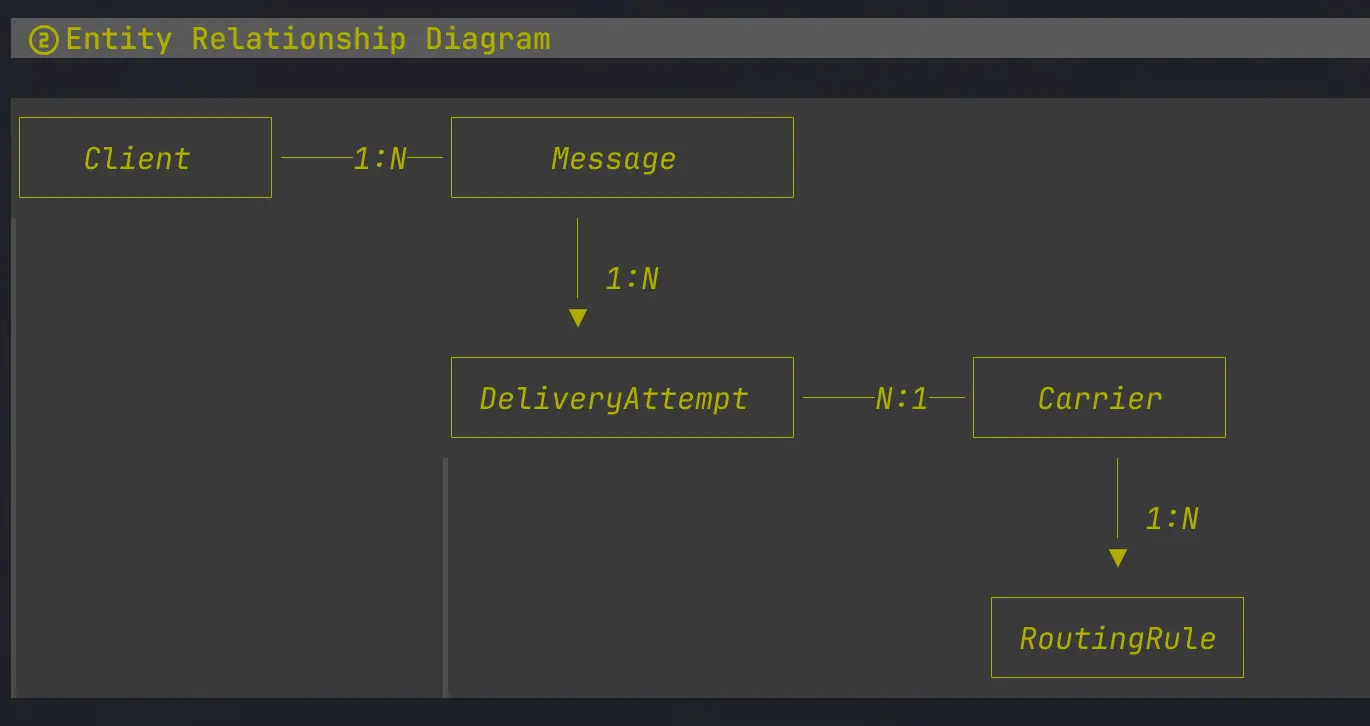
Database schema
A full db schema that will remove any doubts during development about the schema since you can check all of this upfront.
Also validations and associations are defined.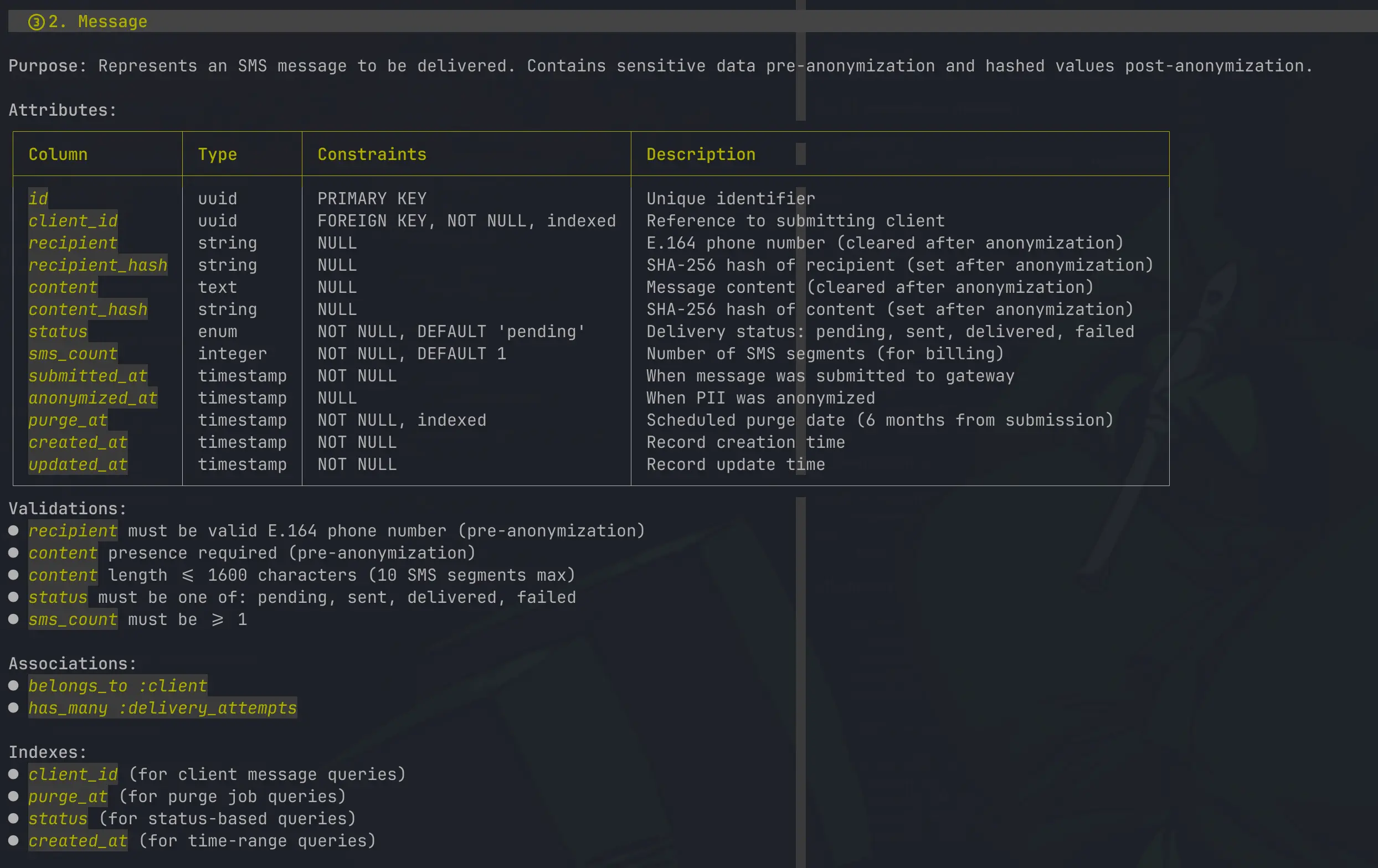
Recap
So let’s recap what we have so far.
- a constitution document describing general coding guidelines
- a plan and user stories for the feature that is to be implemented
- data model
- a detailed research document with data researched regarding the feature that is to be implemented
- a quick start guide on how to set things up
- examples how the API should be called.
Can we please get to the coding part? Not quite, there’s one more step.
Creating tasks
Now it’s time to let the AI create the tasks for the project / feature at hand. Just give it the /tasks command and let Claude Code do it’s thing and generate a very detailed list of tasks.
Once this step was completed I had a list of almost 120 tasks.
As I mentioned earlier, just this alone is so valuable to have. Even if you are a solo dev without a team, these documents keep you on track with with the broken down tasks and all the research documents. It’s easy to pick up development just by reading the existing documents, no need to go digging in the sources to know how to set up the dev environment.
Development
It’s finally time to have some code written. With the /implement command the AI can finally start coding. However, throwing the whole thing at once might not be the best idea since the context will be huge. You can split it up, either tell it to implement a specific phase, a range of tasks or a single task. After which you can /clear the context and restart every phase with a clean context, this works because all the details are written in the markdown files and the AI can pick up where it left off.
The costs and duration
I did this over two days, but this wasn’t my main focus. I just checked in every once in a while to see if any Claude Code Limits where exceeded or if there was something to confirm. All in all I might have spent an hour for this. I have reached the usage limit for Claude just one time, everything was done in the monthly 18$ subscription, which means the real cost for this would have been just a few cents. There were only minimal fixes required, some code duplication to be cleaned, but the app was working and comes with 100% test coverage. The speed from idea to running app was impressive and if I would have dedicated my full attention to this, I could have had this online in production in a few hours after sending the first request to Claude code.
Final Thoughts
This experiment with Spec Kit was indeed a very positive experience and even if I won’t have all projects AI Coded, the systematic breakdown from high-level feature specification to detailed tasks, complete with research and documentation, creates a foundation that would typically take days of planning meetings and back-and-forth discussions. Even if you’re skeptical about AI-generated code, the planning and documentation alone justify using Spec Kit. Having a complete specification, entity relationship diagrams, and a task breakdown before writing a single line of code is invaluable, whether you’re working solo or with a team. For less than a dollar and minimal hands-on time, I went from a rough idea to a fully functional, tested SMS gateway API. More importantly, I have complete documentation that makes future maintenance and feature additions straightforward.
Photo by Chris J. Davis on Unsplash